Дисперсията приема стойности. Дисперсия и стандартно отклонение в MS EXCEL. Математическо очакване на дискретна случайна променлива
Математическото очакване показва около коя числова мярка са групирани стойностите случайна величина. Необходимо е обаче също така да може да се измерва променливостта (променливостта) на случайна променлива спрямо математическото очакване. Такъв индикатор за променливост е математическото очакване на квадрата на разликата между случайната променлива и нейното математическо очакване, а именно M [(X - M [X]) 2].
Определение. дисперсията на случайна променлива x е числото 14 DX] = M [(XM [X]) 2], (3.30)
или DX] = ±f(x T) o(*,-M[X]) 2.
Фигура 3.26 показва формули за изчисляване на разпределението - статистическа вероятност fx;) - както и индикатори: математическо очакване M [X](клетка E9) и дисперсия D [X] (клетка G9).
14 Предлагаме да сравним това определение с определението на дисперсията на извадката
Ориз. 3.26. Формули за изчисляване на m [x] и 0 [X]Таблицата на фиг. 3.27 показва резултатите от изчисляването на математическото очакване m [x]и дисперсия 0 [X]съгласно пример 3.14, както и хистограмата на разпределението m [x]= 4,00 (клетка E9) и дисперсия 0 [X] = 1,00 (клетка B9).
Математическото очакване показва, че стойността на случайната величина хгрупирани около стойност 4.00, чийто брой е 50% от общия брой. Други данни обаче могат да бъдат групирани около същата стойност.

Ориз. 3.27. Таблица и хистограма на разпределението с A / [X] = 4,00 и £> [X] = 1,00
От фиг. 3.28 се вижда, че при математическото очакване [x] = 4.00, дисперсията £> [X] = 2.32 е два пъти по-голяма от тази според данните на фиг. 3.28. 3.27. Съответната хистограма също показва значителна променливост.

Ориз. 3.28. Таблица и хистограма на разпределението с M[X]=4,00 и £>[X]=2,32
Предлагаме да сравним таблиците и графиките на фиг. 3.27 и 3.28 и направете изводи. Имоти дисперсияслучайна променлива, която постоянно се използва във вероятностните статистически методи:
o ако х- случайна променлива, a и b - някои числа, B = ax + b,Че
д= a 2 D[X] (3.31)
(това означава, че числото a като параметър на мащаба значително влияе върху дисперсията, докато числото b - параметърът на смяната не влияе върху стойността на дисперсията);
o ако X 1, X 2, X n са по двойки независими случайни променливи (т.е. X t и X са независими за i Ф j), тогава дисперсията на сумата е равна на сумата от дисперсиите
D = D + D + ... + D . (3,32)
Съотношението за математическото очакване (3.25) и дисперсията (3.32) има важностпри изучаване на свойствата на извадката, тъй като резултатите от наблюденията или измерванията на извадката се разглеждат в математическата статистика като реализации на независими случайни променливи.
Друг показател за променливост е тясно свързан с дисперсията на случайна величина - стандартното отклонение.
Определение. Стандартното отклонение на случайна променлива x е цяло число
SD [Х]= +VD[X]. (3,33)
Така, стандартно отклонениеясно свързани с дисперсията.
В теорията и практиката на статистическите изследвания важна роля играят и специалните функции - така наречените моменти (начални и централни), които са характеристики на случайни величини.
Определение. Началният момент на k-тия ред на случайната променлива хнаречена математическа чакащ к-тастепен на тази стойност:
~ К=М. 15 (3.34)
Определение. Централният момент от k-ти ред на случайната променлива хсе нарича очакване k-та степенотклонения на тази стойност x от нейното математическо очакване:
m = m k, където a = M[X].
За да обозначим моментите на случайни променливи, използваме същите букви като за моментите на вариационната серия, но с допълнителен знак~ ("тилда").
Формули за изчисляване на дискретни моменти (които приемат стойностите хи с вероятност p) и непрекъснато (с плътност на вероятността / x)) произволно
стойностите са дадени в табл. 3.4.
Таблица 3.4
Формули за изчисляване на моментите на случайни величини

Що се отнася до вариационните низове, моментите на дискретни случайни променливи имат подобно значение:
Първи начален момент(¿= 1) случайна променлива Той Хнея математическо очакване:
~ 1 = M [X] = s. (3.36)
Втори централен момент(¿= 2) определя дисперсията 0 [X] на случайната променлива x:
W d(chi - a) 2 g. u \u003d TsH] \u003d (T 2. (3.37)
Трети централен момент(¿= 3) характеризира асиметрията на разпределението на случайната променлива x:
П
Коефициент на асиметрияи разпределението на случайната променлива x има формата:
G \u003d ~ X (chi "a) 3 R и =А. (3,38)
Четвърти централен момент(¿= 4) характеризира стръмността на разпределението на случайната променлива.

Въз основа на сравнение на стойностите на теоретичните и примерните моменти се оценяват параметрите на разпределенията на случайни променливи (вижте например раздели 4 и 5).
Както беше отбелязано по-горе, в математическата статистика се използват две паралелни линии от индикатори: първата е свързана с практиката (това са примерни индикатори), втората се основава на теория (това са индикатори на вероятностен модел). Съотношението на тези показатели е представено в табл. 3.5.
Таблица 3.5
Корелация между показателите на емпиричната извадка и вероятностния модел

Таблица 3.5 продължава

Така че целта Описателна статистикае трансформирането на набор от примерни емпирични данни в система от индикатори - така наречените статистики, свързани с обекти от реалния живот. И така, психолози, учители и други специалисти работят в реалната сфера, чиито обекти са индивиди, групи от индивиди, екипи, характеристиките на които са емпирични показатели. Основната цел на изследването обаче е да се получат нови знания, а знанията съществуват в идеална форма под формата на характеристики на теоретични модели. Това повдига проблема за правилния преход от емпирични показатели на реални обекти към показатели на теоретичен модел. Този преход изисква анализ както на общи методологични подходи, така и на строги математически основи. Основната възможност тук се открива от закона големи числа, теоретичната обосновка за която е предоставена от Яков Бернули (1654-1705), Пафнутий Лвович Чебишев (1821-1894) и други математици от 19 век.
Въпрос. Задача.
1. Разширете понятието случайна променлива.
2. Каква е разликата между дискретни и непрекъснати случайни променливи?
3. От какви елементи се състои вероятностното пространство?
4. Как се изгражда разпределението на дискретна случайна променлива?
5. Как са свързани функцията на плътност A (x) и функцията на разпределение B (x)?
6. Дайте геометрична интерпретация на интеграла Б(ко) = | Л(x) cx = 1.
В теорията на измерванията втората централна точка, т.нар дисперсия резултати от наблюдение или дисперсия на случайна грешка D2.
Нека намерим дисперсията на случайната променлива от предишния пример, използвайки тази формула:

Дисперсията на случайната грешка е характеристика на дисперсията на резултатите от наблюденията спрямо математическото очакване.
Дисперсията има размерността на квадрата на измереното физическо количество, поради което много по-често в метрологичната практика се използва стандартно отклонение (RMS) от резултатите от наблюденията, което е корен квадратен от дисперсията: a = ^ D.X. RMS има размерността на измерената физическа величина.
Плътността на вероятността от резултатите от наблюденията за различни стойности на RMS грешката има следната форма (фиг. 5.4).

Ориз. 5.4
Колкото по-голямо е, толкова по-плоска и "размита" става функцията на разпределение.
Дисперсията има четири свойства.
Имот 1.Дисперсията на постоянна стойност е нула: D(C) = 0.
Доказателство.По дефиниция дисперсията на случайна променлива е равна на разликата между квадратните отклонения на всяка стойност на тази променлива и нейното математическо очакване: D(X) = M[X - M(X)] 2.Тогава D(C) = = M[S - M(S)] 2.В съответствие с първото свойство на математическото очакване (математическото очакване на постоянна стойност е равно на самата стойност), имаме D(C) = Г-ЦА- C) 2 \u003d M (0) 2 \u003d 0. Това също показва, че постоянната стойност запазва същата стойност и няма разсейване.
Имот 2.Константният коефициент може да бъде изваден от дисперсионния знак чрез повдигане на квадрат:
Доказателство.По дефиниция дисперсията на случайна променлива D(CX) = MSH-M(SH) 2].В съответствие с второто свойство на математическото очакване ( постоянен факторможе да бъде изваден от знака за очакване)
Имот 3.Дисперсията на сумата от две независими случайни променливи е равна на сумата от дисперсиите на тези променливи:
Доказателство.Според дисперсионната формула имаме
Отваряйки скобите и използвайки свойството очакване на сумата от няколко количества и произведението на две независими случайни променливи, получаваме
Следствието от това свойство е, че дисперсията на сумата от няколко взаимно независими случайни променливи е равна на сумата от дисперсиите на тези променливи, а също и че дисперсията на сумата от постоянна стойност и случайна променлива е равна на дисперсия на случайна променлива, т.е.
Имот 4.Дисперсията на разликата на две независими случайни променливи е равна на сумата от дисперсиите на тези променливи: D(X-Y) = D(X) + D(Y).
Доказателство.Поради третото свойство D(X-Y) = D(X) + D(-Y).Според второто свойство на дисперсия D(-Y) = (-1) 2 D(Y) = D(Y).следователно
Въз основа на това свойство стандартното отклонение на сумата от краен брой взаимно независими случайни променливи е корен квадратенот сумата на квадратите на стандартните отклонения на тези величини:
Известно е, че според закона за разпределение могат да се намерят числените характеристики на случайна променлива. Това от своя страна означава, че ако няколко случайни променливи имат еднакви закони на разпределение, то техните числени характеристики са еднакви.
Обмисли Пнезависими случайни променливи X r X 2 ,..., X p,които имат едни и същи разпределения и, следователно, едни и същи характеристики (математическо очакване, дисперсия и т.н.). От гледна точка на теорията на измерването най-голям интерес представлява изследването на числените характеристики на средноаритметичното на тези величини.
Означаване на средноаритметичното на разглеждания случаен
количества като  , установете връзка между числови характеристикитова средно аритметично и съответните характеристики на математическото очакване, дисперсията и стандартното отклонение на средното аритметично на случайната променлива.
, установете връзка между числови характеристикитова средно аритметично и съответните характеристики на математическото очакване, дисперсията и стандартното отклонение на средното аритметично на случайната променлива.
1. Математическото очакване на средноаритметичното на еднакво разпределени взаимно несвързани случайни променливи е равно на математическото очакване Авсяко от количествата:
2. Дисперсия на средноаритметичното П Ппъти по-малка от дисперсията двсяко от количествата:
3. Стандартно отклонение на средната аритметична стойност Правномерно разпределени независими случайни променливи в 4pпъти по-малко от стандартното отклонение a на всяко от количествата:
Пример.Стандартното отклонение на всеки 16 еднакво разпределени взаимно независими случайни променливи е равно на 10. Намерете стандартното отклонение на средноаритметичното a* на тези променливи.
Дисперсия в статистикатасе намира като индивидуални стойности на характеристиката в квадрата на . В зависимост от първоначалните данни, тя се определя по формулите за проста и претеглена дисперсия:
1. (за негрупирани данни) се изчислява по формулата:
2. Претеглена дисперсия (за серия от варианти):
 където n е честотата (коефициент на повторяемост X)
където n е честотата (коефициент на повторяемост X)
Пример за намиране на дисперсията
Тази страница описва стандартен пример за намиране на дисперсията, можете също да разгледате други задачи за намирането й
Пример 1. Имаме следните данни за група от 20 ученици кореспондентски отдел. Необходимо е да се изгради интервална серия на разпределението на признака, да се изчисли средната стойност на признака и да се изследва неговата дисперсия
 Нека изградим интервално групиране. Нека определим диапазона на интервала по формулата:
Нека изградим интервално групиране. Нека определим диапазона на интервала по формулата:
![]() където X max е максималната стойност на групиращия признак;
където X max е максималната стойност на групиращия признак;
X min е минималната стойност на групиращия признак;
n е броят на интервалите:
Приемаме n=5. Стъпката е: h \u003d (192 - 159) / 5 \u003d 6,6
Нека направим интервално групиране
 За по-нататъшни изчисления ще изградим спомагателна таблица:
За по-нататъшни изчисления ще изградим спомагателна таблица:
 X'i е средата на интервала. (например средата на интервала 159 - 165.6 = 162.3)
X'i е средата на интервала. (например средата на интервала 159 - 165.6 = 162.3)
Средният растеж на учениците се определя по формулата на среднопретеглената аритметична стойност:
 Определяме дисперсията по формулата:
Определяме дисперсията по формулата:
Формулата на дисперсията може да се преобразува, както следва:
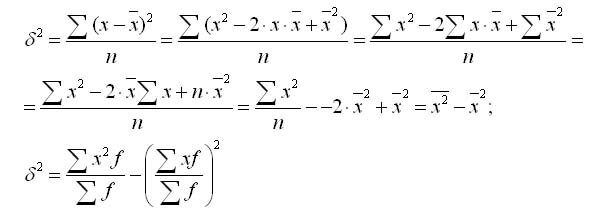
От тази формула следва, че дисперсията е разликата между средната стойност на квадратите на опциите и квадрата и средната стойност.
Дисперсия в вариационна серия с равни интервали по метода на моментите може да се изчисли по следния начин, като се използва второто свойство на дисперсия (разделяне на всички опции на стойността на интервала). Дефиниция на дисперсия, изчислено по метода на моментите, по следната формула отнема по-малко време:

където i е стойността на интервала;
A - условна нула, която е удобна за използване в средата на интервала с най-висока честота;
m1 е квадратът на момента от първи ред;
m2 - момент от втори ред
(ако в статистическа съвкупностзнакът се променя така, че има само две взаимно изключващи се опции, тогава такава променливост се нарича алтернатива) може да се изчисли по формулата:

Замествайки в тази дисперсионна формула q = 1- p, получаваме:

Видове дисперсия
Обща дисперсияизмерва вариацията на даден признак в цялата популация като цяло под влиянието на всички фактори, които причиняват тази вариация. Тя е равна на средния квадрат на отклоненията на отделните стойности на атрибута x от общата средна стойност x и може да се определи като проста дисперсия или претеглена дисперсия.
характеризира случайна вариация, т.е. част от вариацията, която се дължи на влиянието на неотчетени фактори и не зависи от знака-фактор, лежащ в основата на групирането. Тази дисперсия е равна на средния квадрат на отклоненията на отделните стойности на атрибута в групата X от средната аритметична на групата и може да се изчисли като проста дисперсия или като претеглена дисперсия.
По този начин, мерки за дисперсия в рамките на групатавариация на признак в група и се определя по формулата:

където xi - средна група;
ni е броят на единиците в групата.
Например, вътрешногруповите отклонения, които трябва да бъдат определени в задачата за изследване на ефекта от квалификацията на работниците върху нивото на производителността на труда в цеха, показват вариации в производството във всяка група, причинени от всички възможни фактори (техническо състояние на оборудването, наличие на инструменти и материали, възраст на работниците, интензивност на труда и др.), с изключение на разликите в квалификационната категория (в рамките на групата всички работници имат една и съща квалификация).
Средната стойност на дисперсиите в рамките на групата отразява случайната, т.е. онази част от вариацията, която е възникнала под влиянието на всички други фактори, с изключение на фактора за групиране. Изчислява се по формулата:

Той характеризира систематичната вариация на резултантния признак, която се дължи на влиянието на признака-фактор, лежащ в основата на групирането. Тя е равна на средния квадрат на отклоненията на груповите средни стойности от общата средна стойност. Междугруповата дисперсия се изчислява по формулата:

Правило за добавяне на дисперсии в статистиката
Според правило за добавяне на дисперсииобщата дисперсия е равна на сумата от средната стойност на вътрешногруповите и междугруповите дисперсии:
![]()
Значението на това правилое, че общата дисперсия, която възниква под влиянието на всички фактори, е равна на сумата от дисперсиите, които възникват под влиянието на всички други фактори, и дисперсията, която възниква поради групиращия фактор.
Използвайки формулата за добавяне на дисперсии, е възможно да се определи третото неизвестно от две известни дисперсии, както и да се прецени силата на влиянието на атрибута за групиране.
Свойства на дисперсия
1. Ако всички стойности на атрибута се намалят (увеличат) със същата постоянна стойност, тогава дисперсията няма да се промени от това.
2. Ако всички стойности на атрибута се намалят (увеличат) с еднакъв брой пъти n, тогава дисперсията съответно ще намалее (увеличи) с n^2 пъти.
Дисперсията на случайна променлива е мярка за разпространението на стойностите на тази променлива. Малката вариация означава, че стойностите са групирани близо една до друга. Голямото отклонение показва силно разсейване на стойностите. Концепцията за дисперсията на случайна променлива се използва в статистиката. Например, ако сравните дисперсията на стойностите на две величини (като резултатите от наблюденията на пациенти мъже и жени), можете да тествате значимостта на някаква променлива. Дисперсията се използва и при изграждането на статистически модели, тъй като малката дисперсия може да е знак, че пренастройвате стойностите.
стъпки
Примерно изчисляване на дисперсията
- Например, нека анализираме броя на кифлите, продадени в кафене за 6 дни, взети в произволен ред. Извадката има следния вид: 17, 15, 23, 7, 9, 13. Това е извадка, а не съвкупност, тъй като нямаме данни за продадени кифли за всеки ден, в който работи кафенето.
- Ако ви е дадена популация, а не извадка от стойности, преминете към следващия раздел.
-
Запишете формулата за изчисляване на дисперсията на извадката.Дисперсията е мярка за разпространението на стойностите на някакво количество. Колкото по-близо е стойността на дисперсията до нула, толкова по-близо са групирани стойностите. Когато работите с извадка от стойности, използвайте следната формула, за да изчислите дисперсията:
Изчислете средната стойност проби.Означава се като x̅. Средната стойност на извадката се изчислява като нормална средна аритметична стойност: добавете всички стойности в извадката и след това разделете резултата на броя на стойностите в извадката.
- В нашия пример добавете стойностите в извадката: 15 + 17 + 23 + 7 + 9 + 13 = 84
Сега разделете резултата на броя на стойностите в извадката (в нашия пример има 6): 84 ÷ 6 = 14.
Примерна средна x̅ = 14. - Средната стойност на извадката е централната стойност, около която се разпределят стойностите в извадката. Ако стойностите в клъстера на извадката около извадката са средни, тогава дисперсията е малка; в противен случай дисперсията е голяма.
- В нашия пример добавете стойностите в извадката: 15 + 17 + 23 + 7 + 9 + 13 = 84
-
Извадете средната стойност на извадката от всяка стойност в извадката.Сега изчислете разликата x i (\displaystyle x_(i))- x̅, където x i (\displaystyle x_(i))- всяка стойност в извадката. Всеки получен резултат показва степента, до която определена стойност се отклонява от средната стойност на извадката, тоест колко далеч е тази стойност от средната стойност на извадката.
Както беше отбелязано по-горе, сумата от разликите x i (\displaystyle x_(i))- x̅ трябва да е равно на нула. Това означава, че средната дисперсия винаги е нула, което не дава представа за разпространението на стойностите на някакво количество. За да разрешите тази задача, повдигнете на квадрат всяка разлика x i (\displaystyle x_(i))- х. Това ще доведе до получаване само на положителни числа, което при добавяне никога няма да даде 0.
Изчислете сумата на квадратите на разликите.Тоест намерете частта от формулата, която е написана така: ∑[( x i (\displaystyle x_(i))-х) 2 (\displaystyle ^(2))]. Тук знакът Σ означава сумата от квадратните разлики за всяка стойност x i (\displaystyle x_(i))в пробата. Вече намерихте разликите на квадрат (x i (\displaystyle (x_(i))-х) 2 (\displaystyle ^(2))за всяка стойност x i (\displaystyle x_(i))в пробата; сега просто добавете тези квадратчета.
- В нашия пример: 9 + 1 + 81 + 49 + 25 + 1 = 166 .
-
Разделете резултата на n - 1, където n е броят на стойностите в извадката.Преди време, за да изчислят дисперсията на извадката, статистиците просто разделиха резултата на n; в този случай ще получите средната стойност на квадратната дисперсия, която е идеална за описание на дисперсията на дадена проба. Но не забравяйте, че всяка извадка е само малка част от общата съвкупност от стойности. Ако вземете различна проба и направите същите изчисления, ще получите различен резултат. Както се оказва, разделянето на n - 1 (вместо само на n) дава по-добра оценка на дисперсията на съвкупността, което е това, което търсите. Деленето на n - 1 е станало обичайно, така че е включено във формулата за изчисляване на дисперсията на извадката.
Разликата между дисперсията и стандартното отклонение.Имайте предвид, че формулата съдържа експонента, така че дисперсията се измерва в квадратни единици на анализираната стойност. Понякога такава стойност е доста трудна за работа; в такива случаи се използва стандартното отклонение, което е равно на корен квадратен от дисперсията. Ето защо дисперсията на извадката се означава като s 2 (\displaystyle s^(2)), и стандартното отклонение на извадката като s (\displaystyle s).
- В нашия пример примерното стандартно отклонение е: s = √33,2 = 5,76.
Изчисляване на дисперсията на популацията
-
Анализирайте някакъв набор от стойности.Комплектът включва всички стойности на разглежданото количество. Например, ако изучавате възрастта на жителите на Ленинградска област, тогава населението включва възрастта на всички жители на този регион. В случай на работа с агрегат се препоръчва да създадете таблица и да въведете стойностите на агрегата в нея. Разгледайте следния пример:
Запишете формулата за изчисляване на дисперсията на съвкупността.Тъй като популацията включва всички стойности на определено количество, следната формула ви позволява да получите точната стойност на дисперсията на популацията. За да разграничат вариацията на популацията от вариацията на извадката (която е само приблизителна), статистиците използват различни променливи:
Изчислете средната стойност на населението.Когато се работи с генералната съвкупност, нейната средна стойност се означава като μ (mu). Средната популация се изчислява като обичайната средна аритметична стойност: добавете всички стойности в популацията и след това разделете резултата на броя на стойностите в популацията.
Извадете средната популация от всяка стойност в популацията.Колкото по-близо до нула е разликата, толкова по-близо е конкретно значениеза населението означава. Намерете разликата между всяка стойност в популацията и нейната средна стойност и ще получите първи поглед върху разпределението на стойностите.
Квадратирайте всеки получен резултат.Стойностите на разликата ще бъдат както положителни, така и отрицателни; ако поставите тези стойности на числова ос, тогава те ще лежат отдясно и отляво на средната стойност на съвкупността. Това не е подходящо за изчисляване на дисперсия, тъй като положителни и отрицателни числавзаимно се компенсират. Затова повдигнете на квадрат всяка разлика, за да получите изключително положителни числа.
Намерете средната стойност на получените резултати.Открихте колко далеч е всяка стойност в съвкупността от нейната средна стойност. Намерете средната стойност на сумата от квадратните разлики, като я разделите на броя на стойностите в популацията.
-
Свържете това решение с формулата.Ако не разбирате как горното решение е свързано с формулата, по-долу е обяснение на решението:
- Намираме разликата между всяка стойност и средната съвкупност и след това повдигаме на квадрат всяка разлика, тоест получаваме ( x 1 (\displaystyle x_(1)) - μ) 2 (\displaystyle ^(2)), (x 2 (\displaystyle x_(2)) - μ) 2 (\displaystyle ^(2))и така до ( x n (\displaystyle x_(n)) - μ) 2 (\displaystyle ^(2)), Където x n (\displaystyle x_(n))е последната стойност в популацията.
- За да изчислите средната стойност на получените резултати, трябва да намерите тяхната сума и да я разделите на n: (( x 1 (\displaystyle x_(1)) - μ) 2 (\displaystyle ^(2)) + (x 2 (\displaystyle x_(2)) - μ) 2 (\displaystyle ^(2)) + ... + (x n (\displaystyle x_(n)) - μ) 2 (\displaystyle ^(2))) / н
- Сега нека напишем горното обяснение с помощта на променливи: (∑( x i (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2))) / n и получете формула за изчисляване на дисперсията на съвкупността.
Запишете пробните стойности.В повечето случаи само извадки от определени популации са достъпни за статистиците. Например, като правило, статистиците не анализират разходите за поддържане на популацията на всички автомобили в Русия - те анализират произволна извадка от няколко хиляди коли. Такава извадка ще помогне да се определи средната цена на автомобил, но най-вероятно получената стойност ще бъде далеч от реалната.
Нека изчислим вГ-ЦАEXCELдисперсия и стандартно отклонение на извадката. Ние също изчисляваме дисперсията на случайна променлива, ако е известно нейното разпределение.
Първо помислете дисперсия, тогава стандартно отклонение.
Дисперсия на извадката
Дисперсия на извадката (дисперсия на извадката,пробадисперсия) характеризира разпространението на стойностите в масива спрямо .
И трите формули са математически еквивалентни.
От първата формула се вижда, че дисперсия на извадкатае сумата от квадратите на отклоненията на всяка стойност в масива от средноразделено на размера на извадката минус 1.
дисперсия пробиизползва се функцията DISP(), бълг. името на VAR, т.е. ВАРИАНЦИЯ. От MS EXCEL 2010 се препоръчва използването на неговия аналог DISP.V() , англ. името ВАРС, т.е. Дисперсия на пробата. Освен това, започвайки от версията на MS EXCEL 2010, има функция DISP.G (), англ. VARP име, т.е. Популация VARIance, която изчислява дисперсияЗа население. Цялата разлика се свежда до знаменателя: вместо n-1 като DISP.V(), DISP.G() има само n в знаменателя. Преди MS EXCEL 2010 функцията VARP() се използваше за изчисляване на дисперсията на популацията.
Дисперсия на извадката
=КВАДРАТ(Проба)/(БРОЙ(Проба)-1)
=(SUMSQ(Извадка)-БРОЙ(Извадка)*СРЕДНО(Извадка)^2)/ (БРОЙ(Извадка)-1)- обичайната формула
=SUM((Пример -СРЕДНО(Пример))^2)/ (БРОЙ(Пример)-1) –
Дисперсия на извадкатае равно на 0 само ако всички стойности са равни една на друга и съответно са равни средна стойност. Обикновено колкото по-голяма е стойността дисперсия, толкова по-голямо е разпространението на стойностите в масива.
Дисперсия на извадкатае точкова оценка дисперсияразпределение на случайната променлива, от която проба. Относно сградата доверителни интервалипри оценяване дисперсияможе да се прочете в статията.
Дисперсия на случайна променлива
Да изчисля дисперсияслучайна променлива, трябва да я знаете.
За дисперсияслучайната променлива X често използва нотацията Var(X). дисперсияе равно на квадрата на отклонението от средната E(X): Var(X)=E[(X-E(X)) 2 ]
дисперсияизчислено по формулата:

където x i е стойността, която може да приеме случайната променлива, а μ е средната стойност (), р(x) е вероятността случайната променлива да приеме стойността x.
Ако случайната променлива има , тогава дисперсияизчислено по формулата:

Измерение дисперсиясъответства на квадрата на мерната единица на първоначалните стойности. Например, ако стойностите в извадката са измервания на теглото на детайла (в kg), тогава размерът на дисперсията ще бъде kg 2 . Това може да бъде трудно за тълкуване, следователно, за характеризиране на разпространението на стойности, стойност, равна на корен квадратен от дисперсия – стандартно отклонение.
Някои имоти дисперсия:
Var(X+a)=Var(X), където X е случайна променлива, а a е константа.
Var(aХ)=a 2 Var(X)
Var(X)=E[(X-E(X)) 2 ]=E=E(X 2)-E(2*X*E(X))+(E(X)) 2=E(X 2)- 2*E(X)*E(X)+(E(X)) 2 =E(X 2)-(E(X)) 2
Това свойство на дисперсия се използва в статия за линейна регресия.
Var(X+Y)=Var(X) + Var(Y) + 2*Cov(X;Y), където X и Y са случайни променливи, Cov(X;Y) е ковариацията на тези случайни променливи.
Ако случайните променливи са независими, тогава техните ковариацияе 0 и следователно Var(X+Y)=Var(X)+Var(Y). Това свойство на дисперсията се използва в изхода.
Нека покажем това за независими променливи Var(X-Y)=Var(X+Y). Наистина Var(X-Y)= Var(X-Y)= Var(X+(-Y))= Var(X)+Var(-Y)= Var(X)+Var(-Y)= Var( X) + (- 1) 2 Var (Y) \u003d Var (X) + Var (Y) \u003d Var (X + Y). Това свойство на дисперсията се използва за начертаване.
Примерно стандартно отклонение
Примерно стандартно отклонениее мярка за това колко широко са разпръснати стойностите в извадката спрямо техните .
A-приори, стандартно отклонениее равно на корен квадратен от дисперсия:

Стандартно отклонениене взема предвид големината на стойностите в вземане на проби, а само степента на разпръскване на ценностите около тях средата. Нека вземем пример, за да илюстрираме това.
Нека изчислим стандартното отклонение за 2 проби: (1; 5; 9) и (1001; 1005; 1009). И в двата случая s=4. Очевидно е, че съотношението на стандартното отклонение към стойностите на масива е значително различно за пробите. За такива случаи използвайте Коефициентът на вариация(Coefficient of Variation, CV) - отношение стандартно отклонениедо средното аритметика, изразено като процент.
В MS EXCEL 2007 и по-стари версии за изчисление Примерно стандартно отклонениеизползва се функцията =STDEV(), бълг. името STDEV, т.е. стандартно отклонение. От MS EXCEL 2010 се препоръчва използването на неговия аналог = STDEV.B () , англ. име STDEV.S, т.е. Примерно стандартно отклонение.
Освен това, започвайки от версията на MS EXCEL 2010, има функция STDEV.G () , англ. име STDEV.P, т.е. Популация Стандартно отклонение, което изчислява стандартно отклонениеЗа население. Цялата разлика се свежда до знаменателя: вместо n-1 като STDEV.V(), STDEV.G() има само n в знаменателя.
Стандартно отклонениеможе също да се изчисли директно от формулите по-долу (вижте примерния файл)
=SQRT(SQUADROTIV(Проба)/(БРОЙ(Проба)-1))
=SQRT((SUMSQ(Проба)-БРОЙ(Проба)*СРЕДНО(Проба)^2)/(БРОЙ(Проба)-1))
Други мерки за дисперсия
Функцията SQUADRIVE() изчислява с umm на квадратни отклонения на стойностите от техните средата. Тази функция ще върне същия резултат като формулата =VAR.G( проба)*ПРОВЕРКА( проба) , Където проба- препратка към диапазон, съдържащ масив от примерни стойности (). Изчисленията във функцията QUADROTIV() се правят по формулата:

Функцията SROOT() също е мярка за разсейването на набор от данни. Функцията SIROTL() изчислява средната стойност на абсолютните стойности на отклоненията на стойностите от средата. Тази функция ще върне същия резултат като формулата =SUMPRODUCT(ABS(Пример-СРЕДЕН(Пример)))/БРОЙ(Пример), Където проба- препратка към диапазон, съдържащ масив от примерни стойности.
Изчисленията във функцията SROOTKL () се правят по формулата:





